
研究方向
本实验室紧紧围绕数据科学与技术,依托北师港浸大在统计学、数学和计算机科学与技术等学科积累的优势,积极探索基于数据的新科学范式,深入研究基础性重大理论问题,并探索学科间的理论、方法横向交叉及理论与应用领域的纵向交叉应用。充分发挥申请单位所拥有的人才和团队优势、地缘经济优势以及机制优势。建立服务广东省、服务粤港澳大湾区、服务横琴粤澳深度合作区的科研平台。
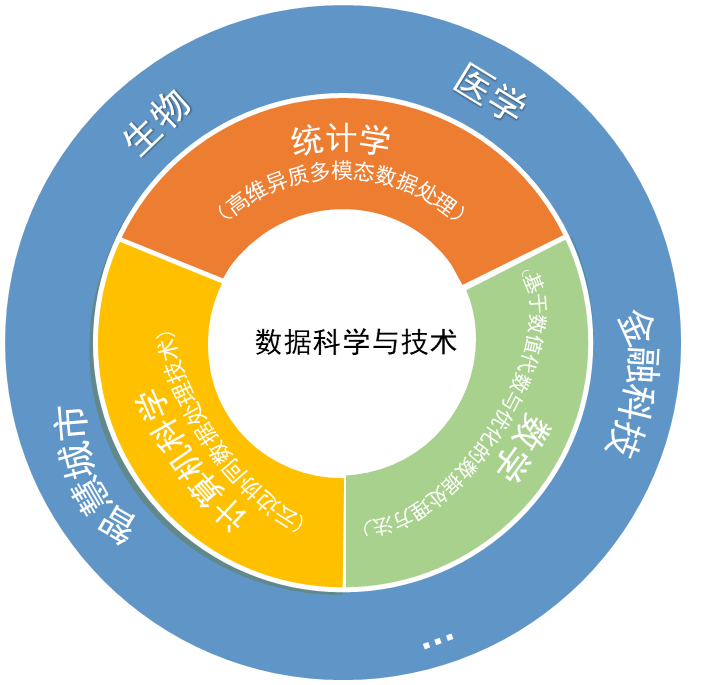
实验室研究方向概览
数据科学与技术正在改变着人们的工作、生活与思维模式,进而对文化、技术和学术研究产生了深远影响。数据科学时代给各学科领域带来了新的机遇,即研究范式的转变,出现了区别于传统科学研究中沿用至今的“知识范式”的新研究范式——“数据范式”。同时,随着相关技术发展的日新月异,数据的获得不再是瓶颈或难题,各学科领域中的传统知识与新兴数据之间的矛盾日益突出,传统知识无法解释和有效利用新兴的大数据,进而促使传统理论与方法发生革命性变化。数据科学中的大量理论基础根植于传统学科如统计学、数学和计算机科学中,聚集了不同专业中的数据科学中的共性理念、理论、方法、术语与工具;同时数据科学的发展又对以上三个学科提出了挑战和难题,使得通过学科之间的交叉结合解决数据时代的新问题成为了必然的趋势。
本实验室的研究方向涵盖与粤港澳大湾区产业规划相关的数据科学交叉应用领域,包括但不限于以下三个重点方向:
重点研究方向一:高维异质多模态数据处理及医疗健康大数据应用
1. 医学图像处理
在临床医学领域,通过对CT、PET、MRI、fMRI等多模态图像数据进行分析与建模,有助于对肿瘤,心血管疾病,阿尔茨海默症等多种疾病进行病理推断和病情预测;在生物领域,通过对血液涂片图像、细胞荧光显微镜图像、组织学图像等不同类型图像进行分析,提取图像型数据的生物标记,以此对人体生理机能进行推断和预测;在传染病预警监测领域,基于肺部CT图像数据的处理为医疗机构提供精准诊断工具,并且结合多状态转移模型预测疫情首发和复发概率以及基于大数据下的混合类型变量选择方法识别出疫情爆发的规律和重要影响指标,有助于政府部门制定干预和疫情管理政策;在公共卫生领域,心血管图像数据的处理将为心血管健康管理提供建议,减少心脏病发病风险。本方向将研究带有图像协变量的模型分析问题,利用函数型数据的混合效应模型刻画图像数据的异质性和空间分布特点,并且在此基础上提出一类新的模型刻画目标数据(例如发病率, 发病时间等)与图像数据之间的关系。在预测方面,当图像数据与目标数据的关系形式未知时,创新性地提出一套新的预测方法,基于降维后的图像信息对目标数据的值进行预测。本研究将充分拓展和推广现有的图像分析方法,研究带图像变量模型中的降维、估计和预测问题。
2. 个体化精准医疗
由于不同个体在生化指标、生活习惯、遗传信息等方面存在显著性差异,最优治疗方案对于不同个体往往有不同的选择。因此在最优治疗方案的选择上,对个体异质信息的考虑和运用尤为重要。本方向将结合混合效应模型和机器学习模型,利用随机效应刻画个体异质性,并在此基础上提出新的机器学习方法对个体进行分类,从而筛选出精准的治疗方案。对于具有高维混合数据类型的个体,本研究将创新性地提出一类具有复杂混合数据的模型,结合新的特征提取和机器学习方法,对个体进行信息降维和精准医疗方案的选择。研究将充分拓展和推广现有的方法,研究个体化精准医疗中的降维、估计和预测问题。
重点研究方向二:基于数值代数与优化的数据处理方法及金融风险管理应用
1. 随机化方法及其在矩阵奇异值分解计算过程中的应用
随机化方法已被证明是各种矩阵计算任务中的宝贵工具,例如在矩阵向量乘积和低维矩阵逼近方面的应用。我们将考虑随机化的矩阵奇异值分解并探讨这种算法的效率及稳健性。
2. 针对高维数据的数值代数与优化方法
在一些应用中,数据集并不能用一个矩阵描述,而是需要用张量表示。如果对此张量进行存储,那么在接下来的计算过程中存储要求一般很快会超过计算机的可用存储资源。这种与张量的维度相关的指数增长现象通常被称为维度诅咒。所以,一般我们要对张量进行近似。张量近似一般涉及到一个非线性函数在相关高维空间的表示问题。我们将研究针对这个非线性函数的不同的逼近方法,并探讨相应的计算复杂度问题。
3. 可解析分解(Interpretable Factorizations)技术
为了解决实际中金融数据矩阵的奇异值分解没有直观解释的问题, 我们将研究现有的两类常用的可解析分解(Interpretable Factorizations)技术,即CUR逼近方法和非负矩阵分解方法,并探讨他们在特定金融数据分析中的应用。
4. 机器学习在金融数据分析中的应用
在数值代数与优化方法的理论基础之上,我们将结合现有的机器学习和神经网络的理论,对金融市场中的数据进行分析,以期得到风险评估及管理、投资策略设计等方面的新思路。特别地,我们将应用机器学习中的迁移学习算法并利用神经网络架构,将市场表现正常时的预测模型迁移至极端小概率事件发生的场景下,从而实现在不对数据分布作预设的情况下有效提取及预测尾部风险。
重点研究方向三:云边协同数据处理技术及智慧城市应用
1. 云边协同与传输存储
构建基于云-边-端两级双向预测传输机制的数据传输方案,将传统集中式云端计算任务迁移到分布式的边缘端,从而充分利用边缘端的计算能力和存储能力;设计分层存储方法,通过生成数据块和冗余块,并将它们按划分策略分别存储在云-边-端三层来实现数据隐私的保护和数据可用性的保障,使得即使云端存储的数据被泄露,由于缺少了另外两层存储的数据,原始数据不能被复原,从而保护了隐私。
2. 数据融合与处理
设计基于自适应模型更新的数据清洗方法,对各种信息源给出的有用信息进行采集、传输、综合、过滤、相关与合成,处理和协调多信息源、多平台和多用户系统的数据信息。将执行计算和存储的资源分别部署在云端和边缘端,协同利用云端和边缘端进行异常数据检测模型训练,并在边缘端部署该模型以对底层采集的数据进行实时异常检测。经边缘端筛选过滤后的可靠数据再上传到云端,以保证数据处理系统各单位与汇集中心间的连通性与及时通信、数据处理和决策。
3. 智能数据挖掘与分析
对海量的城市数据进行自动分析、自动分类、自动汇总、自动发现和描述数据中的趋势、标记异常等等,从而将获取的有用信息和知识应用于决策支持系统。因此,在智慧城市数据检索过程中,需要设计分层检索结构和构建隐式索引,并部署在边缘层,边缘端通过隐藏索引关联信息与原始数据查询结果来实现不同层级(云边端服务器)之间的透明化数据传输。
4. 孪生数字城市
利用视觉传感器、测绘技术等建立城市的外部3D映像,并结合云边协同的传输与存储、数据融合与处理、智能挖掘与分析等相关技术,逐层构建出其他更加丰富的应用,如城市时空信息交互平台等。这些应用将从不同的角度来对城市交通、电力、管线、人流、安保等信息分类和管理,如围绕时间维度的应用、围绕空间维度的应用和围绕不同实体维度的应用等。
